CLIP 모델로 한국어 자연어 이미지 검색기 만들기 후기
OpenAI의 CLIP과 같은 구조를 사용하는 uform 모델로 한국어 자연어 검색기를 만들어보았습니다. 한국어 뿐만이 아닌, 영어등등 21개국어를 할 수 있는 모델이기에 범용성이 높습니다.
2024-01-10 배포
아무런 정보 없이 사진만 주어졌을때 딸기를 검색하면 딸기 사진이 나오고, 해변가에 앉아 있는 고양이를 검색하면 해변가에 앉아 있는 고양이가 나오는 마법 같은 검색엔진이 있을까요?
2021년 1월 CLIP 모델이 나오면서 정교한 이미지 검색이 가능해졌습니다.

아래 사진을 보시면 상당히 정교하다는것을 알 수 있습니다.
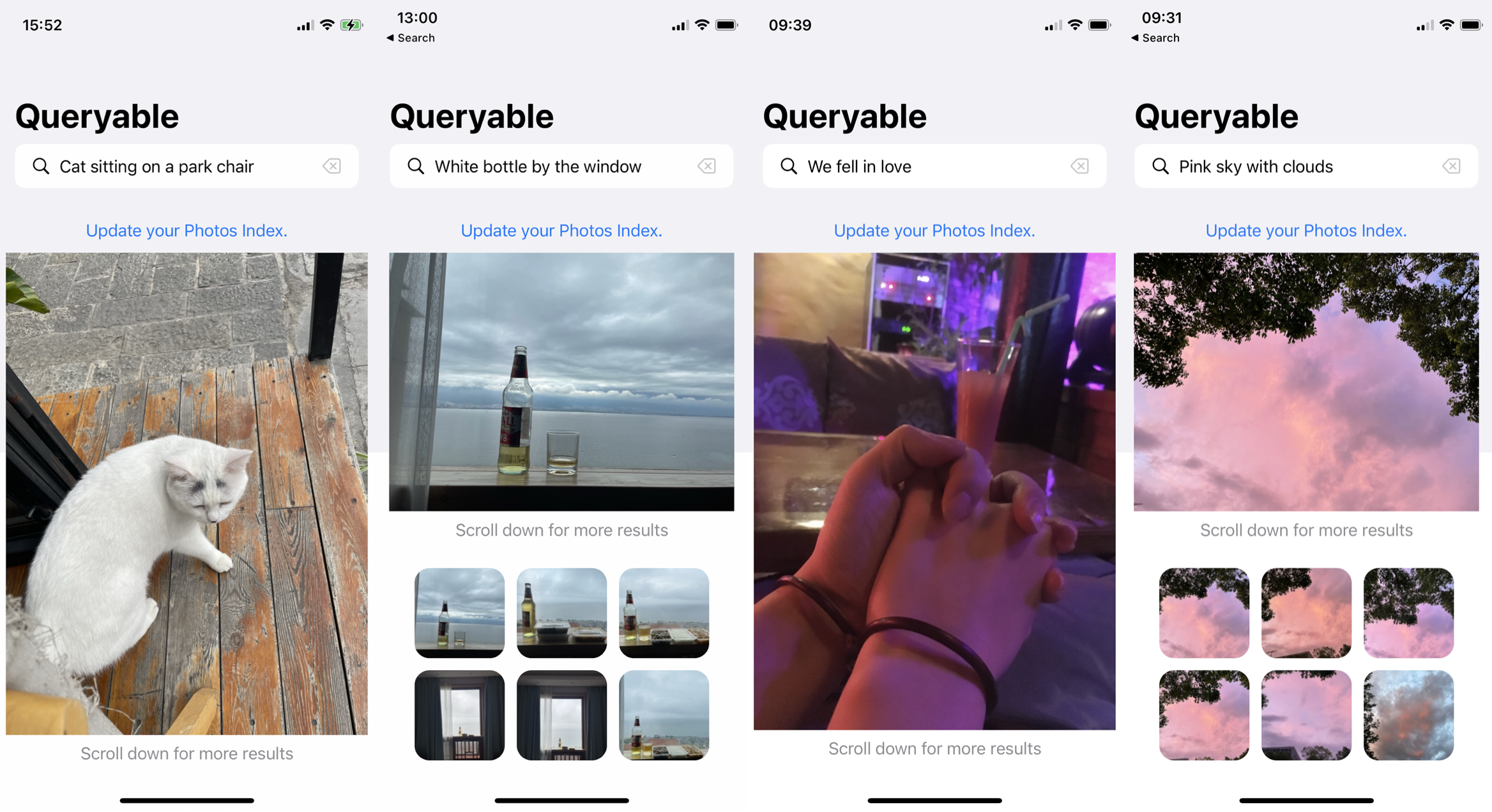
CLIP 모델과 uform 모델 관계, 그리고 자연어 이미지 검색기 만들기
OpenAI의 CLIP을 1/100의 데이터셋으로 이겨버리기
uform 개발사 unum 블로그에 따르면 uform은 OpenAI의 CLIP보다 100배 작은, 그러니까 1% 정도 수준의 데이터셋만으로 동등하거나 더 우월한 성능을 발휘하는 모델이라고 합니다.
거기에 unum은 번역 모델을 사용하여 uform의 데이터셋을 번역해서 한국어 포함 21개 국어를 할 수 있게 만들었습니다.
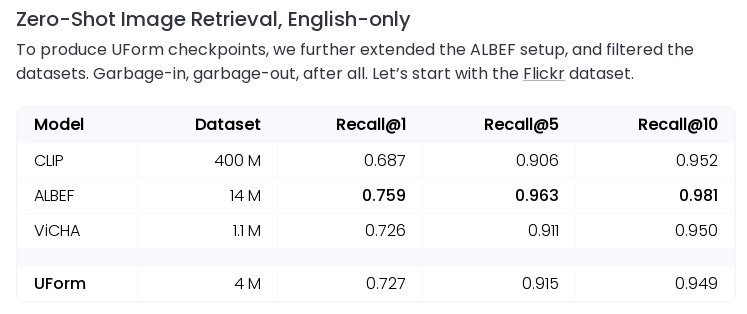
벤치마크를 보면 영어 기준 정말 CLIP과 동등하거나 더 우월한 성능을 발휘하는것을 볼 수 있습니다.
원본 CLIP은 영어 밖에 못하니, 다른 언어 부문은 당연하게도 uform이 승을 가져갑니다.
OpenAI를 이긴 방법:
먼저 CLIP이 제작된 방법을 알아봅시다.
-
인터넷에서 크롤링을 통해 4억개의 이미지를 다운로드 합니다.
-
그리고 해당 이미지 주변에 있는 128 토큰의 글자를 이미지랑 매칭 시킵니다.
-
학습!
아무래도 데이터셋의 오염이 심하고 제대로 된 설명이라고 기대할 수도 없을겁니다.
그러니 정제된 400만개의 데이터셋만으로 OpenAI를 이긴거죠, 데이터셋의 질이 중요한가봅니다.
자연어 이미지 검색기 만들기
그럼 이제 uform으로 검색기를 만들 차례이지요.
대략적인 구조는 아래와 같습니다:
- uform으로 이미지를 임베딩한다.
- usearch로 임베딩된 벡터를 인덱스에 인덱싱한다.
- usearch로 인덱스를 검색한다.
1, 2번 코드부터 보여드리겠습니다.
pip install uform usearch
이렇게 라이브러리 두개만 설치해주세요.
import uform
from usearch.index import Index
from PIL import Image
import os
import pickle
from tqdm import tqdm
from concurrent.futures import ThreadPoolExecutor
model = uform.get_model('unum-cloud/uform-vl-multilingual-v2')
index = Index(ndim=256)
image_directory = '/directory/image/'
index_to_filename = {}
def add_image_to_index(key, image_path):
image = Image.open(image_path)
image_data = model.preprocess_image(image)
image_embedding = model.encode_image(image_data).detach().numpy()
index.add(key, image_embedding.flatten(), copy=True)
index_to_filename[key] = image_path
def process_image(args):
key, filename = args
add_image_to_index(key, os.path.join(image_directory, filename))
image_files = [f for f in os.listdir(image_directory) if f.endswith(('.jpg', '.jpeg', '.png'))]
with ThreadPoolExecutor(max_workers=4) as executor:
list(tqdm(executor.map(process_image, enumerate(image_files)), total=len(image_files), desc="Processing Images"))
with open('index_to_filename.pkl', 'wb') as f:
pickle.dump(index_to_filename, f)
index.save("index.usearch")
인덱싱은 ARM altra 4 core vm 기준 사진 8000장에 45분 정도 소요 되었습니다.
import uform
from usearch.index import Index
import numpy as np
import pickle
model = uform.get_model('unum-cloud/uform-vl-multilingual-v2')
index = Index(ndim=256, metric='cos')
index.load("index.usearch")
with open('index_to_filename.pkl', 'rb') as f:
index_to_filename = pickle.load(f)
def search_images_by_text(query, top_k=5):
tokens = model.preprocess_text(query)
query_embedding = model.encode_text(tokens).detach().numpy()
matches = index.search(query_embedding.flatten(), top_k)
return [index_to_filename[key] for key in matches.keys]
example_query = "dog with cat"
similar_images = search_images_by_text(example_query)
print("Similar Images:", similar_images)
상위 5개의 결과를 가져옵니다. 시간은 대략 10초 넘게 걸리는것 같네요.





사이트에 있는 1만 2000장에 사진 중에서 쿼리와 가장 연관성 있다고 uform이 판단한 상위 5개의 이미지입니다.
애초에 1만 2000장에 사진 중 강아지 사진이 거의 없다는걸 생각하면, 나름 잘 찾은것 같습니다.
특히 고양이와 강아지가 외형상 구분이 헷갈리기 쉬운 동물이라는걸 생각해봤을때, 고양이가 나온건 어느정도 이해 가능할것 같습니다.
저희 사이트는 고양이 사진이 매우 많기 때문이죠.
사이트에다가도 API로 연동해서 배포하려고 계획은 세워두었으나 시간이 잘 안나네요.
결론
uform 모델에서 보았듯이 ML에서는 데이터셋의 질이 상당히 중요하다는것을 알 수 있을것 같습니다.
즐거운 AI 생활 되시길 바랍니다. 또한 제공해드린 예시 코드가 도움이 되었으면 좋겠네요.
감사합니다.